在MySQL的建表SQL里,在HTTP的请求和响应的头部里,我们常常见到Unicode与UTF-8的出现。但很多时候即使是作为软件开发者,也很难讲清楚Unicode与UTF-8具体的含义与原理。事实上,如果我们在开发软件的时候”惯性”得选了UTF-8的编码方式,基本不会遇到字符编码相关的问题。
可是了解Unicode与UTF-8,对于软件的国际化和理解字符串类型的存储,解释与传输等又是如此重要。所以我在学习清楚这些概念之后,在这边文章里做一下记录和说明。
基础概念明晰
Unicode是一种字符集character set,UTF-8是一种字符编码方式,这是我们都具有的常规的概念。可是细究起来,什么是字符集?什么是字符编码?甚至什么是字符?这是我们需要先弄清楚的术语。
字符 CHARACTER
字符本身反而是最容易混淆,与上下文相关的概念。不过在这里我们为了说明上的方便,将字符限定为“具有语义价值的书面语言的最小组成部分”。比如单个的汉字”一”,单个的英语字母”a”等等都是一个字符。
字符集 CHARACTER SETS
字符集就是一组字符的集合。比如26个小写英文字母是一个字符集,全部汉字是一个字符集,百家姓是一个字符集。
与计算机相关的字符集,比如ASCII字符集包含128个字符,包括了26个基本拉丁字母、阿拉伯数字和英式标点符号以及一些控制字符。Unicode字符集则可以说是包含了地球上所有有意义的语言字符,这也是当下Unicode字符集成为主流的原因。
编码字符集 CODED CHARACTER SETS
字符和字符集还是通用概念,编码字符集就进入了计算机范围的概念。编码字符集是为每个字符分配了唯一编号的字符集,该编号就是代码点,表示编码字符集中字符的位置。
计算机中存在很多编码字符集,Unicode是其中一种。
代码点 CODE POINT
为了在计算机中明确的引入字符,将每一个字符与一个数字相关联,这个数字称为代码点(注意,这里并不完全准确,因为有的字符既可以对应一个代码点,也可能是多个代码点的组合,不过这可以留在完整理解字符与编码之后再去深究,这里为了描述方便,我们先假设一个字符对应一个代码点,也就是映射到一个代码点)。
字符<->代码点之间的映射关系完全是由字符集的人为规定来的,例如在ISO 8859-1(也称为Latin1)的编码字符集中,字母é的十进制代码点值为233;而在ISO 8859-5编码字符集中,字符ù的十进制代码点值也为233。
字符编码 character encoding
计算机只处理数字,每个字符(代码点)在计算机中的存储其实是唯一的二进制数字的序列,比如”00000100”,当我们在保存字符进入计算机的时候,每个字符应该转换为怎样的二进制序列;当操作系统从存储中读取到二进制序列的时候,怎么知道对应的是哪个字符呢?
这就是字符编码的作用,定义了 代码点 <-> 二进制存储序列 之间互相转化的关系。这里可能会有疑问,代码点本来就是数字,直接将数字的字面值存入二进制序列不就可以了吗?比如ASCII中的字符A的十进制代码点为65,对应的二进制序列为“01000001”。利用字面值进行互相转化当然是一种对应关系,事实上标准ASCII就是利用的这种对应关系。不过这就像是选择哈希表的散列函数,f(n)=n是一种最简单的散列函数,但是我们也可以选择其他的散列函数。由于各种各样的原因(因为规则是人定的,制定的时候肯定考虑了多种因素,因此有的字符编码例如UTF-8不是采用的这种字面值对应关系)。
除了ASCII,还有许多字符编码标准(例如ISO 8859系列中的标准)对给定字符使用单个字节,并且编码是直接映射到编码字符集中字符的字面值位置。例如,ISO 8859-1编码字符集中的字母A位于第65个字符位置(从零开始),并使用值为65的字节值进行编码以在计算机中表示,也就是字节表示的数值就是编码字符集中的代码点的数值。
但是对于Unicode字符集来说,事情并不那么简单。尽管Unicode编码字符集中字母á的代码点始终为225(十进制),但在UTF-8中,它在计算机中以两个字节表示。换句话说,在UTF-8编码字符集的数值和该字符的编码字节值之间不存在简单的字面值的的一对一映射。
UTF-8是一种字符编码方式。
Unicode 与 UTF-8
在计算机的发展史中,出现了各种各样的编码字符集,也出现了形形色色的字符编码方式。那为什么现在Unicode成为了最广泛使用的字符集,UTF-8成为了最流行的字符编码方式呢?
历史视角
简短的发展介绍。
现代计算机毕竟是从美国开始发展的,当然最早输入的字符就是英文字符,字符集也是围绕着基本英文字母为中心的字符集。值得讨论的早期的字符集是标准的ASCII字符集,ASCII字符集只包含26个基本拉丁字母、阿拉伯数字和英式标点符号,以及一些老旧的控制字符。仅需7bits存储,定义了128个数,代码点的范围是用十进制表示是0-127。只能满足现代美国英语字符的输入与显示。
随着计算机的迅猛发展与普及,非英语地区的用户也有输入自己语言的需要,需要字符集能够表示更多的字符,ASCII字符集显然不能满足。因为ASCII只使用了7bits,后面计算机主流是采用8bits字节,所以很多利用了单字节中的第8bit(128-255代码点)进行扩展实现,产生了许多种混乱的实现方案。这些方案在代码点128以下都和标准ASCII中的实现相同,但是从128到255代码点各有自己的实现方案。
利用单字节的第8位也只是妥协方案,毕竟考虑到具有几千个字符的亚洲语言,8bits无法表示这么多字符。虽然产生了类似于DBCS字符集“double byte character set双字节字符集”,其中一些字符存储在一个字节中,而其他字符存储在另一个字节中。但是字符编码与处理方案设计得并不完善,在字符串中向前移动很容易,但是几乎不可能向后移动。而且各地区各有一套不同的DBCS实现,相互之间根本无法互通,所以仍然是处理非常混乱的字符集。
不同的组织已经组合了不同的字符并为它们创建了编码。一组可能仅涵盖拉丁语的西欧语言,另一组只可能涵盖中文等等。遗憾的是,不能保证应用程序将支持所有编码,也不能保证给定的编码将支持表示给定语言的所有需求。此外,通常不可能在同一网页或数据库中组合不同的编码,因此使用“传统”编码方法支持多语言页面通常是非常困难的。
Unicode
既然各种各样的字符集及编码方式带来了极大的混乱,那就创建一个足够大的能够包含地球上所有语言的字符集,定义一个统一的编码方式。Unicode应运而生。
Unicode是由统一码联盟(Unicode Consortium)创造的一个大型的单一字符集,旨在包含世界上任何书写系统所需的所有字符,包括古代脚本(如楔形文字,哥特式和埃及象形文字)。它的目标是,并且在很大程度上已经是已编码的所有其他字符集的超集。
Unicode在0x0000到0x10FFFF的范围内定义了1,114,112个代码点的代码空间。通常,通过写“U+”后跟其十六进制数来表示Unicode代码点。例如”U+0041”表示大写英文字母A。
UTF-8
那么Unicode的编码方式是怎样的呢?
这里首先要注意,一套字符集可以有多种编码方式。就像一个哈希表可以有多个散列函数一样。
早期的Unicode编码方式是UCS-2,将代码点存储进固定的两个字节,并且有区分高端high-endian和低端low-endian模式存储。因为高低端模式的混乱,固定两字节存储可能带来的存储浪费,以及已经有很多ANSI或者DBCS字符集文件的存在,导致Unicode在早期并未得到广泛承认与使用。
UTF-8(Unicode Transformation Format 8-bit)编码格式因此被发明出来。UTF-8是一种可变宽度字符编码,能够使用一到四个8位字节对Unicode中的所有1,112,064个有效代码点进行编码。
它旨在向后兼容ASCII。Unicode的前128个字符与ASCII一一对应,使用与ASCII具有相同二进制值的单个八位字节进行编码,因此有效的ASCII文本也是有效的UTF-8编码的Unicode文本,很好的兼容了旧的英文文本处理字符集。另外,具有较低数值的代码点(往往更频繁地出现)使用较少的字节进行编码。
因为UTF-8对于存储空间的有效利用,可容纳全部Unicode字符的广阔范围,对于ASCII字符集的向后兼容,同时没有大端小端字节序的规则的限制(字节序对于UTF-8编码格式无意义bom),因此UTF-8得到了广泛运用。目前超过%92的网页使用了UTF-8编码格式。
实际上有许多其他编码Unicode的方法。例如UTF-7,它很像UTF-8,但保证高位总是为零,所以如果你必须通过某种认为7bits是足够的老旧的电子邮件系统传递Unicode,仍然可以完整传递。还有UTF-32,它以固定4个字节存储每个代码点,它具有很好的属性,每个代码点以相同的字节数存储,但是,存在大量的存储空间的浪费。
在下图中,第一行数字表示Unicode编码字符集中字符的位置。其他行显示用于表示特定字符编码中的该字符的字节值。
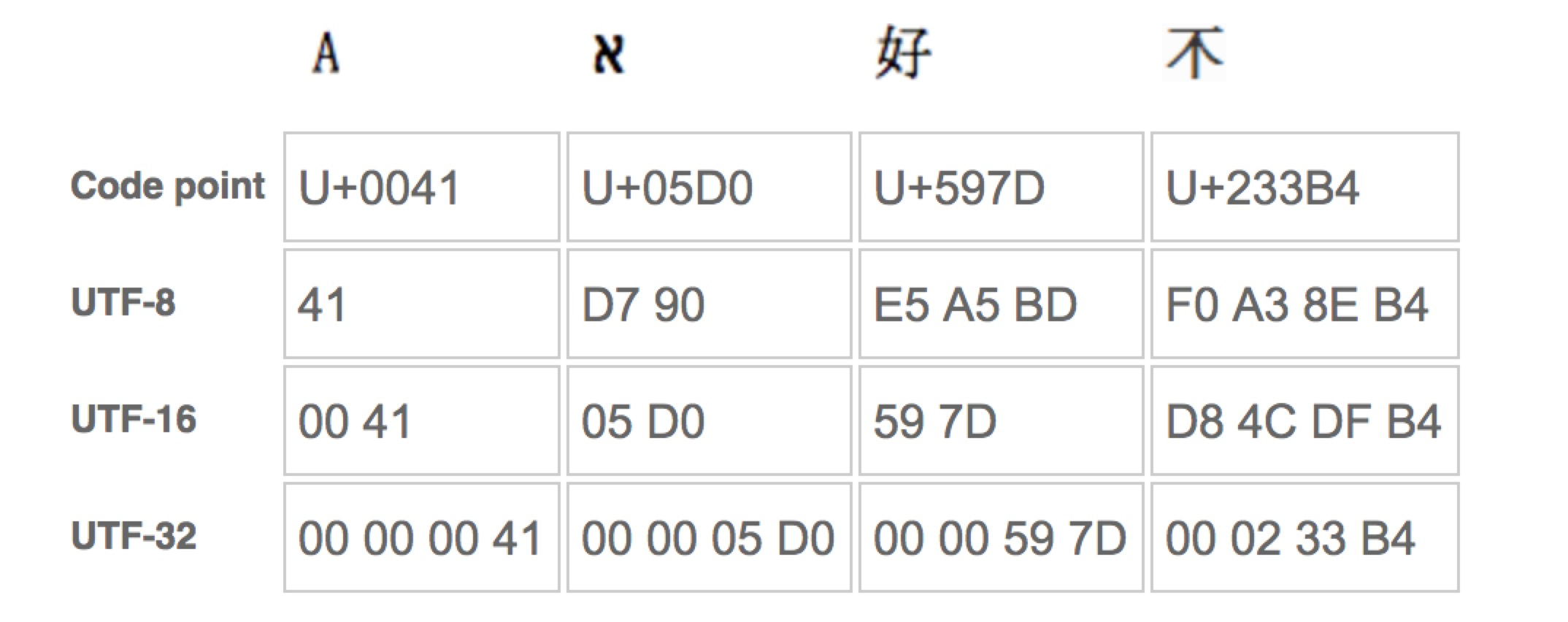
意义
所以这篇文章的结论是,如果需要指定字符编码方式的话,请一定指定UTF-8,O(∩_∩)O哈哈~,似乎回到了开头我们总是见到UTF-8的编码方式,不过现在我们已经知道为什么要指定UTF-8的编码方式。对于开发人员来说,不知道字符编码方式的情况下,字符串也就无从谈起。知其然,也知其所以然。
参考
https://www.w3.org/International/questions/qa-what-is-encoding
https://www.w3.org/International/articles/definitions-characters/#charsets
https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/
http://www.utf-8.com/
https://en.wikipedia.org/w/index.php?title=UTF-8&oldid=891776243
https://en.wikipedia.org/w/index.php?title=Unicode&oldid=8924396
https://en.wikipedia.org/w/index.php?title=Byte_order_mark&oldid=891750318